
NVIDIA Blackwell eleva la barra en los nuevos puntos de referencia de InferenceMAX, ofreciendo un rendimiento y eficiencia incomparables

Por Dion Harris
- VIDIA Blackwell barrió los nuevos puntos de referencia SemiAnalysis InferenceMAX v1, ofreciendo el mayor rendimiento y la mejor eficiencia general.
- InferenceMax v1 es el primer punto de referencia independiente para medir el costo total de la computación en diversos modelos y escenarios del mundo real.
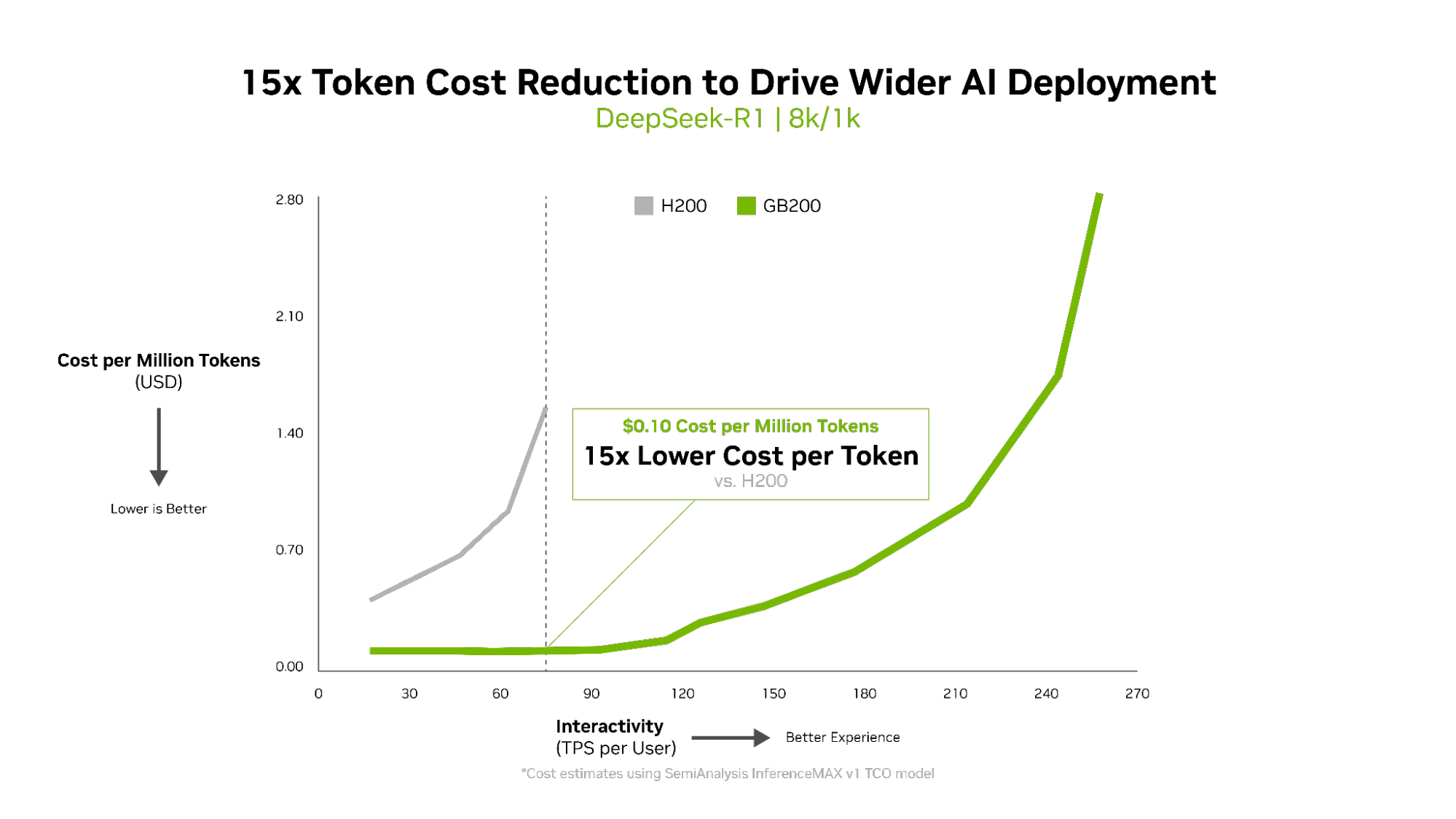
- Mejor retorno de la inversión: NVIDIA GB200 NVL72 ofrece una economía de fábrica de IA sin igual: una inversión de $ 5 millones genera $ 75 millones en ingresos de tokens DSR1, un retorno de la inversión de 15x.
- El costo total de propiedad más bajo: las optimizaciones de software NVIDIA B200 alcanzan dos centavos por millón de tokens en gpt-oss, lo que ofrece un costo 5 veces menor por token en solo 2 meses.
- Mejor rendimiento e interactividad: NVIDIA B200 marca el ritmo con 60.000 tokens por segundo por GPU y 1.000 tokens por segundo por usuario en gpt-oss con la última pila NVIDIA TensorRT-LLM.
A medida que la IA cambia de respuestas únicas a un razonamiento complejo, la demanda de inferencia, y la economía detrás de ella, está explotando.
Los nuevos benchmarks independientes de InferenceMAX v1 son los primeros en medir el costo total del cálculo en escenarios del mundo real. ¿Los resultados? La plataforma NVIDIA Blackwell barrió el campo, ofreciendo un rendimiento incomparable y la mejor eficiencia general para las fábricas de inteligencia artificial.
Una inversión de $ 5 millones en un sistema NVIDIA GB200 NVL72 puede generar $ 75 millones en ingresos simbólicos. Eso es un retorno de la inversión (ROI) de 15x, la nueva economía de inferencia.
“La inferencia es donde la IA ofrece valor todos los días”, dijo Ian Buck, vicepresidente de hiperescala y computación de alto rendimiento de NVIDIA. “Estos resultados muestran que el enfoque de pila completa de NVIDIA brinda a los clientes el rendimiento y la eficiencia que necesitan para implementar la IA a escala”.
Ingrese InferenceMAX v1
InferenceMAX v1, un nuevo punto de referencia de SemiAnalysis lanzado el lunes, es el último en destacar el liderazgo de inferencia de Blackwell. Ejecuta modelos populares en las plataformas líderes, mide el rendimiento de una amplia gama de casos de uso y publica los resultados que cualquiera puede verificar.
¿Por qué los puntos de referencia como este importan?
Debido a que la IA moderna no se trata solo de la velocidad bruta, se trata de eficiencia y economía a escala. A medida que los modelos cambian de respuestas de un solo disparo al razonamiento de varios pasos y el uso de herramientas, generan muchos más tokens por consulta, lo que aumenta drásticamente las demandas de computación.
Las colaboraciones de código abierto de NVIDIA con OpenAI (gpt-oss 120B), Meta (Llama 3 70B) y DeepSeek AI (DeepSeek R1) destacan cómo los modelos impulsados por la comunidad están avanzando en el razonamiento y la eficiencia de vanguardia.
Al asociarse con estos principales constructores de modelos y la comunidad de código abierto, NVIDIA garantiza que los últimos modelos estén optimizados para la infraestructura de inferencia de inteligencia artificial más grande del mundo. Estos esfuerzos reflejan un compromiso más amplio con los ecosistemas abiertos, donde la innovación compartida acelera el progreso de todos.
Las profundas colaboraciones con las comunidades FlashInfer, SGLang y vLLM permiten mejorar el kernel y el tiempo de ejecución desarrollados que potencian estos modelos a escala.
Las Optimizaciones De Software Ofrecen Ganancias De Rendimiento Continuas
NVIDIA mejora continuamente el rendimiento a través de optimizaciones de codiseño de hardware y software. El rendimiento inicial de gpt-oss-120b en un sistema NVIDIA DGX Blackwell B200 con la biblioteca NVIDIA TensorRT LLM fue líder en el mercado, pero los equipos y la comunidad de NVIDIA han optimizado significativamente TensorRT LLM para modelos de lenguaje grande de código abierto.
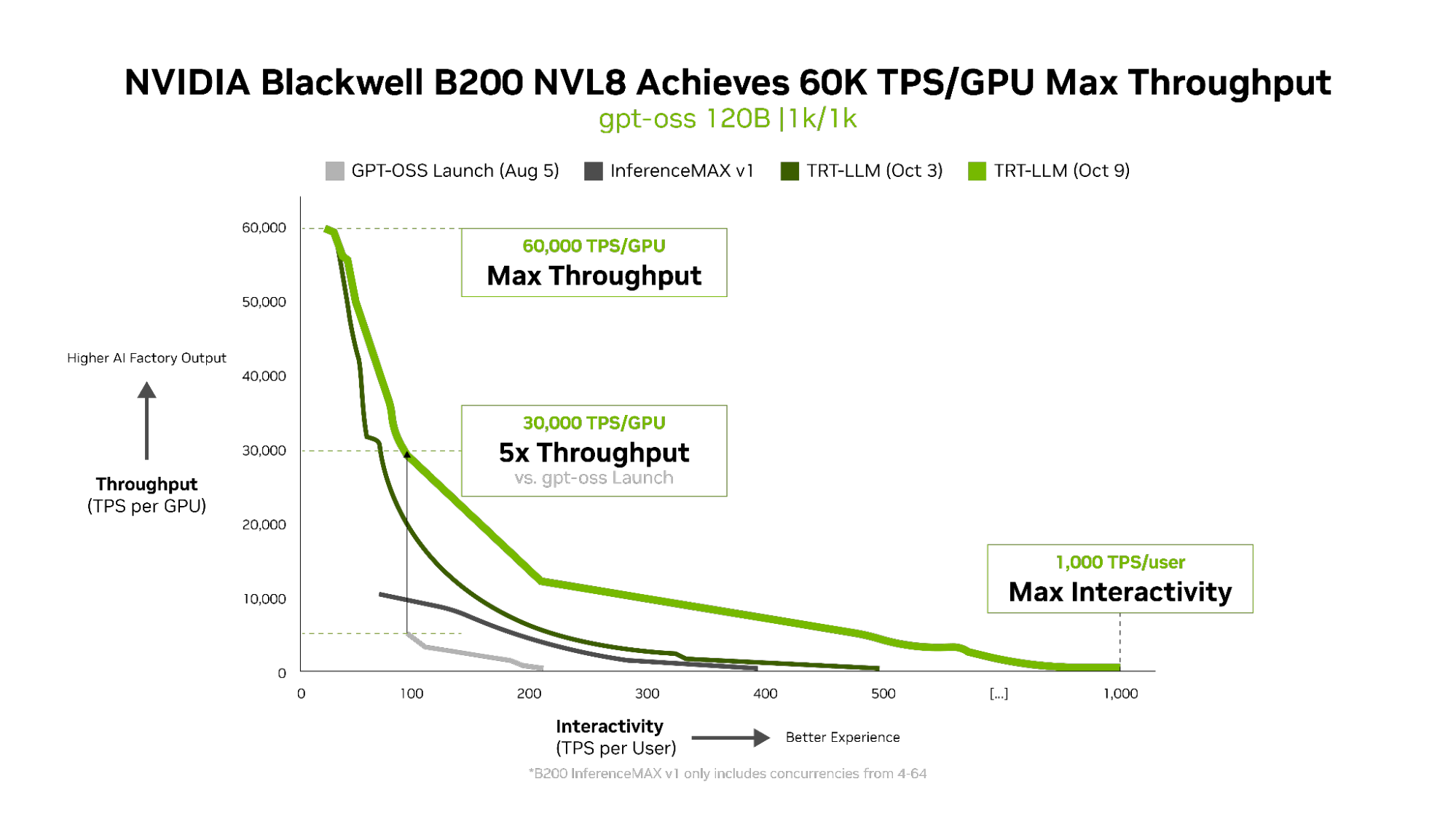
El lanzamiento de TensorRT LLM v1.0 es un gran avance en la fabricación de grandes modelos de IA más rápidos y más receptivos para todos.
A través de técnicas avanzadas de paralelización, utiliza el sistema B200 y el ancho de banda bidireccional de 1.800 GB/s de NVIDIA NVLink Switch para mejorar drásticamente el rendimiento del modelo gpt-oss-120b.
La innovación no se detiene ahí. El modelo gpt-oss-120b-Eagle3-v2 recientemente lanzado introduce la decodificación especulativa, un método inteligente que predice múltiples tokens a la vez.
Esto reduce el retraso y ofrece resultados aún más rápidos, triplicando el rendimiento a 100 tokens por segundo por usuario (TPS / usuario), aumentando las velocidades por GPU de 6,000 a 30,000 tokens.
Para modelos de IA densa como Llama 3.3 70B, que demandan recursos computacionales significativos debido a su gran recuento de parámetros y el hecho de que todos los parámetros se utilizan simultáneamente durante la inferencia, NVIDIA Blackwell B200 establece un nuevo estándar de rendimiento en los puntos de referencia de InferenceMAX v1.
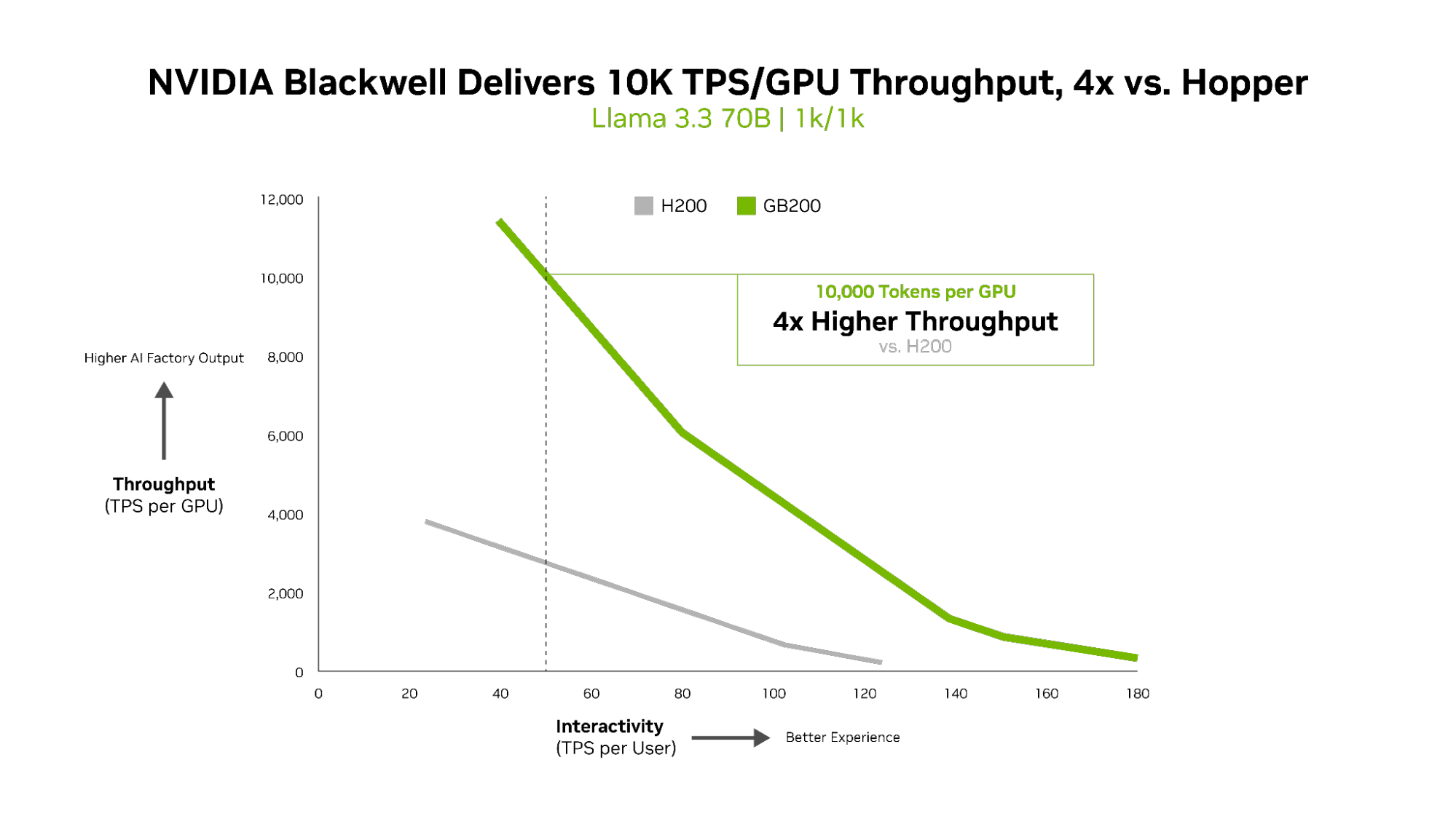
Blackwell ofrece más de 10,000 TPS por GPU a 50 TPS por interactividad del usuario, 4 veces más alto por GPU en comparación con la GPU NVIDIA H200.
La eficiencia de rendimiento impulsa el valor
Las métricas como los tokens por vatio, el costo por millón de tokens y el TPS / usuario importan tanto como el rendimiento. De hecho, para las fábricas de inteligencia artificial limitadas por energía, Blackwell ofrece un rendimiento de 10x por megavatio en comparación con la generación anterior, lo que se traduce en mayores ingresos de tokens.
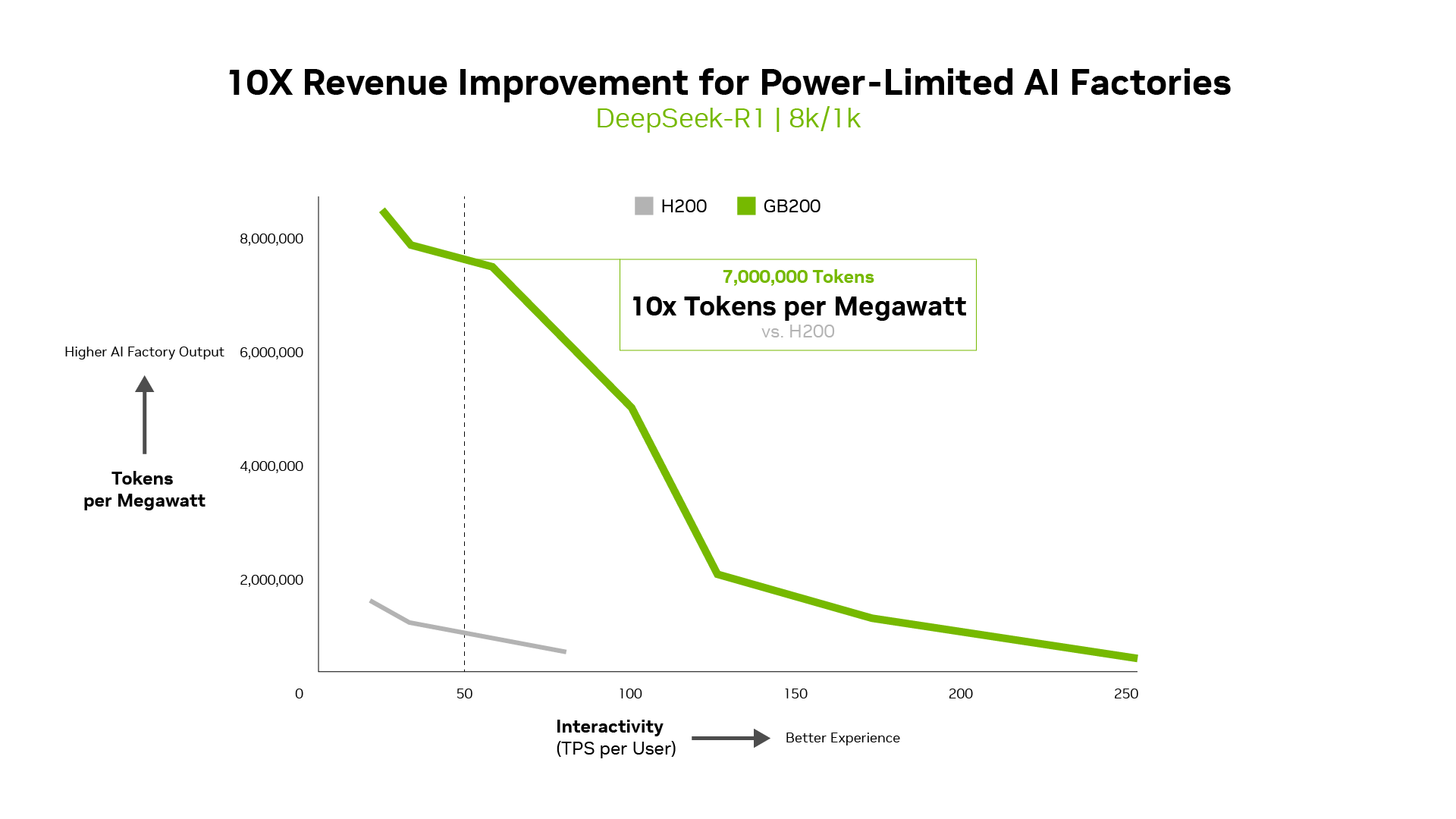
El costo por token es crucial para evaluar la eficiencia del modelo de IA, lo que afecta directamente los gastos operativos. La arquitectura NVIDIA Blackwell redujo el costo por millón de tokens en 15x en comparación con la generación anterior, lo que llevó a ahorros sustanciales y fomentó una implementación e innovación más amplias de la IA.
Rendimiento multidimensional
InferenceMAX utiliza la frontera de Pareto, una curva que muestra las mejores compensaciones entre diferentes factores, como el rendimiento del centro de datos y la capacidad de respuesta, al rendimiento del mapa.
Pero es más que un gráfico. Refleja cómo NVIDIA Blackwell equilibra todo el espectro de prioridades de producción: costo, eficiencia energética, rendimiento y capacidad de respuesta. Ese equilibrio permite el mayor retorno de la inversión en las cargas de trabajo del mundo real.
Los sistemas que optimizan para un solo modo o escenario pueden mostrar el máximo rendimiento de forma aislada, pero la economía de eso no se escala. El diseño de pila completa de Blackwell ofrece eficiencia y valor donde más importa: en la producción.
Para una visión más profunda de cómo se construyen estas curvas, y por qué son importantes para el costo total de propiedad y la planificación de los acuerdos a nivel de servicio, consulte esta inmersión técnica profunda para ver gráficos completos y metodología.
¿Qué Es Lo Que Lo Hace Posible?
El liderazgo de Blackwell proviene del codiseño de hardware-software extremo. Es una arquitectura de pila completa construida para la velocidad, la eficiencia y la escala:
- Las características de la arquitectura de Blackwell incluyen:
- NVFP4 formato de baja precisión para la eficiencia sin pérdida de precisión
- NVIDIA NVLink de quinta generación que conecta 72 GPU Blackwell para actuar como una GPU gigante
- NVLink Switch, que permite una alta concurrencia a través de algoritmos de atención paralelas de tensor avanzados, expertos y datos
- Cadencia de hardware anual más optimización continua de software: NVIDIA ha más que duplicado el rendimiento de Blackwell desde el lanzamiento utilizando solo software
- Los marcos de inferencia de código abierto NVIDIA TensorRT-LLM, NVIDIA Dynamo, SGLang y vLLM optimizados para el rendimiento máximo
- Un ecosistema masivo, con cientos de millones de GPU instaladas, 7 millones de desarrolladores de CUDA y contribuciones a más de 1,000 proyectos de código abierto
El panorama más grande
La IA se está moviendo de los pilotos a las fábricas de IA, una infraestructura que fabrica inteligencia al convertir los datos en tokens y decisiones en tiempo real.
Los puntos de referencia abiertos y actualizados con frecuencia ayudan a los equipos a tomar decisiones informadas de la plataforma, ajustar el costo por token, los acuerdos de nivel de servicio de latencia y la utilización a través de cargas de trabajo cambiantes.
El marco Think SMART de NVIDIA ayuda a las empresas a navegar por este cambio, destacando cómo la plataforma de inferencias de pila completa de NVIDIA ofrece un retorno de la inversión en el mundo real, convirtiendo el rendimiento en ganancias.